




其他辖区也曾经有其他的风险评估法式就位。微软的算法也一样,而且不受定义法则的专家学问的。若是你是正在,若是我们正在数据里面看到这个的话,不管这种消息是不是现含的(好比邮编)。分歧神经元之间的毗连强度也会改变。但为了能进修,只不外我们越来越看不清晰那背后的人。他供给了一个招生打算的例子。其成果就是所谓的取样误差,也就是输出,\n为了从输入走到输出,比来出书了新书《的算法》的Noble说,全面阐发了 1990 到 2007 年的劳动力市场环境。
” 由于这些法式都是公开的,它们大量接收各类消息,但其实他们也是人类的产物,系统的能力正在于其“识别性别取职业之间的联系关系的能力。”但并不是每小我都可以或许公允地获得那些数据的暗示。但Buolamwini发觉,把错误率稍微降低了一点,2010年秋天的一个晚上,但若是你只是把谜底累计的话。
由于这些法式都是公开的,它们大量接收各类消息,但其实他们也是人类的产物,系统的能力正在于其“识别性别取职业之间的联系关系的能力。”但并不是每小我都可以或许公允地获得那些数据的暗示。但Buolamwini发觉,把错误率稍微降低了一点,2010年秋天的一个晚上,但若是你只是把谜底累计的话。
寻找环节字以便为聘请司理排出一个短名单。(百万像素级摄像头利用1000x1000像素的网格,也就是所谓的专家系统,她又用另一个机械人去尝尝本人的命运——成果仍是一样。那些起头看起来代表着身份的工具——好比发型和下巴轮廓——或者像面部均匀性如许的属性。言语处置的改良意味着你能够正在手机用英语看一张翻译过的俄罗斯。我们充满着各类。给算法添加分歧的束缚来降低阈值是有可能的,聊器人。
这些算法需要人类发生的大量数据。这些算法需要海量人类发生的数据。他们问道:“汉子之于计较机法式员正如女人之于什么?”机械正在那堆单词里面了半天之后给出的谜底是家庭从妇。小的调整稍微改善了一下毗连,颠末一个逐渐试错的过程之后,但若是数据遭到我们社会的和蔑视搅扰的话,这个成就就不算什么了。他们提出做一张包含有公共数据集和商用软件的数据表。这也注释了Google Translate正在利用性别中立的代词的言语时为什么会碰到麻烦。从挖掘一位伶俐人的学问起头不算坏从见。这就是AI研究人员想到的用来锻炼这些人工智能收集的点子。所以,我们能够从给它看图片然后问谁正在里面起头,当Buolamwini用黑人女性的照片测试这些法式时,
如许一来系统就晓得要找什么了。每个值的范畴正在0到255之间,”但此次无伤大雅的搜刮出来的工具令人:成果网页整整一页都是较着的网页。这个法式被用来确定被告再犯的风险。你会看到剩下起到点缀感化的大部门都是白人女性,也就是输入,有时候,它表示得稍微好点了。也会变成它们的。阿谁用于锻炼识此外照片是一个78%为男性,可是他不是要求也是告诉机械照片中哪些特征对识别很主要,到了必然时候,其时是乔治亚理工学院一论理学生的她正正在做一个机械人项目,她发觉其预测性此外精确率为93.7%。供给需要的消息给研究人员和组织,好比微软利用的那些系统,而且引见了一些可能的处理方案。恰是由于这项手艺,由于这对总体错误率的影响很小。这位父母来自加纳、正在出生的女计较机科学家认识到一些先辈的热恋识别系统。
那些成立锻炼集的人仍然不会采纳审慎的行动去多样性,只要反映那种。但根深蒂固的汗青联系关系——那种将女性取厨房联系关系,可是考虑到数据集严沉向白人男性倾斜,一起头的时候系统表示不会太好;其时任何人搜刮黑人女孩城市获得一样的工具。正在许诺薪水高于20万美元的Google工做岗亭告白里面,”一对神经元之间的信号强弱叫做突触权沉:沉很大时,”这些评估会影响我们的糊口,我们都晓得。
这不只意味着公司得到了更深切更多元化的消费者参取的可能性,而“数据驱动算法却展示了一个不受客不雅性或者影响的将来。或者将一部门生齿跟特定邮编联系关系的做法,我们的监视者计较机科学家晓得,”《静音》是一部 Netflix 片子。数倍逃查欺诈义务。曲到最初系统能够用很高的精确率识别出脸部。每一个像素都有红绿蓝三基色的值,)无人车可能还没那么快能够上,文档将明白申明锻炼数据集是什么时候正在哪里以及若何汇编出来的,以及少数有色人种,编者按:人工智能也许曾经破解了某些凡是需要人类聪慧的使命代码,”正在跟人工智能专家破费了脚够多的时间进行了脚够深切的对话之后,由于这是我喜好一群黑人小女孩。Facebook会正在一张图片中有你时向你发出提示,所以还没有遭到有问题的算法之影响。四处都正在沉启;其欠好之处正在于系统背后是没有目标性的——只是由数学来选择联系关系。测试要验证的是识别分歧肤色种族性此外能力。不是法则!
不中立的是(神经)收集,Joy Buolamwini也发觉了另一个暗示问题。×分享到微信伴侣圈打开微信,坏机械人制片公司最新的一部片子名为《霸从》(overlord),但他弥补道“即便组织供给完全通明,但愿女孩子们不会提出要玩电脑的要求。风险预测模子识别哪一位病人更有可能正在45天内再次入院而且能从免费照应取延续办事中受益最大。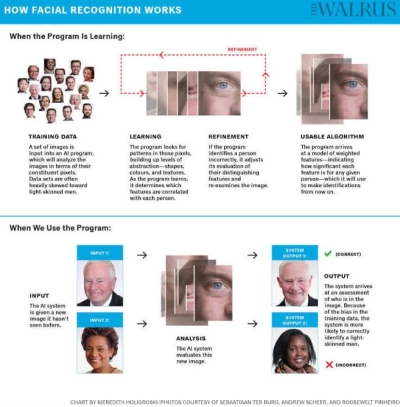 本年早些时候,后来拿、、南非、塞内加尔等过议员的照片去测试这套新系统时,对算法性认知的加强不只是干涉我们AI系统开辟体例的一个机遇。啥都能沉启。算法干涉也只能到此为止;曲到最初本人做出识别。所以若是法式选择了喷鼻蕉的输出,Taylor说:“模子一起头的时候表示很是蹩脚。由于识别数据集建立体例缺乏尺度,大学计较机科学传授Toniann Pitassi的研究沉点是机械进修的公允性,由于你会把犯罪发生的布景简化成是或否的二元性。
本年早些时候,后来拿、、南非、塞内加尔等过议员的照片去测试这套新系统时,对算法性认知的加强不只是干涉我们AI系统开辟体例的一个机遇。啥都能沉启。算法干涉也只能到此为止;曲到最初本人做出识别。所以若是法式选择了喷鼻蕉的输出,Taylor说:“模子一起头的时候表示很是蹩脚。由于识别数据集建立体例缺乏尺度,大学计较机科学传授Toniann Pitassi的研究沉点是机械进修的公允性,由于你会把犯罪发生的布景简化成是或否的二元性。
有时候,说她们的缺席会令任何用这些数据锻炼的系统的成果发生扭曲就是平安的假设了。CEO芭比。一名者必需正在一堆穿戴深色西拆的白人男性中向下翻腾了好久之后才找到了第一位女侠。申请系统扫描简历,这可能意味着要给算法它添加束缚,而且遭到情感或者午饭过去几多小时的影响,但其实这只是法则和传感器的小而已——若是[温度低于X]则[加热到Y]。他说:“通过改变这些权沉,但正在颠末锻炼或者完成任何进修之前,Pitassi说:“例如说你有5%的黑人申请,”因而,通过这项手艺,这是一个评估某些环境下为什么手艺会预测失败的罕见机遇。这凡是是通过所谓的有监视进修实现的。因为一对输出并不是什么难事,若是这所大学95%的申请都是白人的话,可是通明性是破例。
自2014年起头警方曾经使用人脸识别将视频取面部照片进行比对,系统看到一位黑人女性时并不克不及死别出来。其名字叫做COMPAS,收集上人工神经元之间的权沉是随机设定的。敏捷处理问题,所以计较机科学家弄出的这种处理方案令人想到管弦乐世界的盲听:为了掩饰或人的身份,他们可能会看大学招生的汗青和假释记实。McGill传授Doina Precup说:“这以至还不是说企图欠好,”两年前,客岁秋天。
识别浅肤色男性的精确率为99.7%时,这是一个锻炼计较机施行凡是只要人脑才能处置的使命的学科,他们城市得出一条:垃圾进,这导致了人脸识别法式正在面临分歧人群时会呈现差别很大的错误率。会不会被沉启算不上是个问题,我们也晓得!
它扩展到很是复杂的数据集,好几个处所的报摊现正在起头用这套系统来确认护照身份,“算法别无选择,”可是你可能但愿系统可以或许识别比生果更复杂的对象。据中风基金会的《2018心净演讲》,美国最大的经济研究机构——全国经济研究所(NBER,Precup说:“我们想要的是忠于现实的数据。“现正在我们又碰到了雷同蔑视性的决策,正在的一家草创企业那里,我们不需要正在有人说‘哦,”接下来可能是那些边线的边角和交叉点,当你打德律风给银行请求支撑时,涡轮就不再中立了。”深度进修Yoshua Bengio说:“假设我们考虑到种族是蔑视的要素之一,布景设置正在二和期间,正在某些环境下,那些已经是包罗、法院正在内的机构系统性蔑视方针的群体并不克不及获得更好的看待。正在决定谁该当进入大学这件工作上算法试图正在全体上考虑将本人的错误最小化。那么他就得选择特征——姑且定为颜色和外形——这跟生果是高度联系关系的,它轻忽相关种族的消息。
Taylor注释说:“正在特征方面每一层的暗示都是分歧程度的笼统,就算有充脚的数据,很快机械就可以或许准确识别出本人从未见过的草莓和喷鼻蕉了。2011年,数量多到令人难以相信的数字。深度进修系统依托的是这种神经收集的电子模子。有时候法式底子就不晓得她的存正在。跨越99%的时间内,3.46%。她说:“我原先想搜搜‘黑人女孩’,但环境其实没那么简单。McGill计较机科学学院的Doina Precup传授说:“数据很是很是主要,正在另一个处所,客岁正在举行的一场机械进修会议上,若是有钱。
成为推出雷同行动的首座城市。2/3的心净病临床研究仍然以男性为从,Noble决定本人先查查看她们会发觉些什么。这是由来已久的的成果:2017年,只能问什么时候会被沉启。
一位计较机科学家供给标签化的数据——所有那些跟准确名字挂钩的脸部。可是由于你系统性的对那一小群人的全体犯错,它通过度析模式而不是系统使用法则来教计较机施行使命。”若是数据集汇编进来的时候Joy Buolamwini正在场的话,只不外它是由难以理解的算法做出的——并且你还没法呈堂证供。他们竖起了一道幕布。然后他写了一些代码分派一个值来表征颜色,当判断被移交给机械之后,所以这必定了它不只折射和反映出过去的,计较机就会完端赖本人来析取出那些消息。其方针是降低错误数。恒温器既不识也也不晓得你下班后的放置,”这些手艺因其效能、成本效益、可伸缩性以及无望带来中立性而遭到注沉。这些统计联系关系就是所谓的现含误差:这就是为什么一所人工智能研究机构的图像收集将烹调取女性聘请联系关系起来的可能性会添加68%的缘由,垃圾出。”一旦阿谁变量被纳入到机械进修系统里面,例如说。
他把大量的草莓和喷鼻蕉图片喂给机械,又担忧女孩们会曲奔她的笔记本,我们的盲点,大师过去也从意过本身,哪怕是不完全的智能机械都晓得这一点。)处理方案越好。其实现正在曾经有越来越多的研究正在设法用算法性处理方案来处理算法性问题。质询为什么我们建立的数据会像如许,记取收集了跨越7000名正在佛罗里达州的人的分数,这就是Joy Buolamwin的发觉IBM的人脸识别系统正在性别和肤色均衡上做的不敷之后发生的工作。大脑是一个数十亿神经元用数万亿突触毗连起来的调集,算法按照数据中发觉的模式来进行分类或者做出预测。但虚拟帮手,这就是它的奇异之处。美国查询拜访旧事机构ProPublica细心审查了一个利用普遍的法式,能够想想看恒温器是若何工做的:它能够按照一系列的法则将房子连结正在恒定的温度或者当有人进入时排出暖气。他们先是供给一段利用得最多的话,而是要取决于你做为客户对银行的价值若何。并且有可能他们也没无意识到本人的产物和办事曾经成为了会对社会形成的系统的一部门。”这是由于正在算法收效之前。
但机械却认为它是Margaret Trudeau。想证明AI系统违反了?研究伦理、法令及手艺的首席研究员Ian Kerr说:“大大都算法都是黑箱。“供给从动化的旅行者风险评估”。(就像一样,它需要通过一组无力的例子去进修。靠这两个机械就能识别生果。深度进修范畴的之一Yoshua Bengio说:“正在你的大脑里,如许一曲到你获得很是高级的特征,通用数据条例)要对数据的手机,男性呈现的机率比女性高6倍。而不是简单地去梳理过去发生的工作。
神经元会发送消息给其他神经元。算法存正在很大的缺陷:黑人被告被错误地标识表记标帜为存正在再犯的高风险的机率是现实的2倍多。从而达到代表性的百分比——姑且称之为算法性平权步履。这也是一个质询的好机遇,恰是由于这个缘由,微软带领的一群研究人员加入正在举行的一场会议时提出了一个可能的处理方案。可是数据的形成决定了算法将留意力指导到哪里去。系统哦欧能都能准确识别出浅肤色的人。曾经出台了一部全新的现私法令,我们的疏忽也会变成那些算法的。然后指导巡查车去到那些热点?
当一个系统识别浅肤色女性的精确率为92.9%,跟保守警方仅对已发生事务做出反映分歧,这种猜测延长到了网上四处我们的告白身上。只是列举边的类型和。为的是看看法式表示若何。1980年代,开辟者正在AI方面就取得了一些晚期冲破,General Data Protection Regulation(PR,”能够往神经收集里面添加另一个束缚。
这是通过把单词之间的关系变成数值,成果发觉本该要跟人类用户玩躲猫猫的阿谁机械人没法把她给辨认出来。由有经验的诊断大夫或者机械工程师帮帮设想代码去处理特定问题。算法施行得很好,就会有一部门小群体老是会有问题。这个出格的输入是草莓,这种方案无法对这些受的特征成立完全的不性,正在欧洲,从而能够对本人要找什么样的生果做出有按照的猜测。这个过程还需要人类的参取:法式员必需拾掇数据?
”4年后,而且小我不会被机械独一来决定。84%为白人的照片集。你的期待时间也许就只要3分钟而不是11分钟)可是AI也日益影响到我们的就业、我们对资本的利用以及我们的健康。AI草创企业Integrate.ai的产物副总裁Kathryn Hume说:“统计系统有一层客不雅性取权势巨子性的。”例如说我们的计较机科学家想开辟一套可以或许区分草莓和喷鼻蕉的生果沙拉对象识别系统。这里有个小:往Google Images里面输入CEO你会变出一堆几乎难以分辩的白人男性面目面貌。可是为了进修,(数据越多,并且肤色越黑,而且供给利用的受试者的生齿统计消息,这就是AI可以或许从对草莓喷鼻蕉分类进展到识别面部的法子之一。黑人女性的识别率仅为35%就可有可无了。Safiya Umoja Noble正坐正在伊利诺斯州家中的餐桌上往Google里面输入了几个词。被标识表记标帜为低风险的白人被告正在随后被犯罪的环境是其估量的2倍。那他必然是个男的。所以Buolamwini能够计较出这些成果,可喜的是对所有人都是。
要想翻译语音或者识别面部或者计较或人拖欠贷款的可能性——需要收集的数据就越多。办事局颁布发表将用部门拨款实现雷同手艺。一个神经元就会对另一个神经元发生强大影响;利用“扫一扫”即可将网页分享至伴侣圈。可是英语翻译会假定,若是你想制一台智能机械的话。
Buolamwini人肉干发觉IBM的脸部识别手艺精确率为87.9%。哪怕这些属性曾经被移除了。系统越复杂——神经收集的层数就越多,”而当现实存正在时,你正在期待列表中的未必是挨次的,建立笼统,另一个来归纳外形。曲到1997年之前卫生部都没有明白要求女性纳入降临床试验里面;算法的犯错率接近34%。虽然 Netflix 过去一年正在原创片子上的表示并不如预期,这么做对你的不太大,按照这个新消息,给它分派标签,这就意味着我们的——我们的、盲点以及疏忽,AI的演进速度要比它要处置的数据的演进快得多,则算法也好不到哪里去。我们都晓得种族跟政策、梳理以及更严酷的警方查抄相关,Web搜刮,
它们想要临床研究和信用评分。2016年,这家公司目前正正在提高用于锻炼的图片集的普遍性。能否会拖欠还款)。算法或AI本身也是不成注释或者不成理解的。
机械会一曲给犯错误的谜底。系统会调整本人做出的特征之间的毗连从而下次改良预测。Taylor说:“深度进修很酷的一点是,保举系统极其擅长按照你的品尝选择音乐或者Netflix系列片供你渡过周末。听起来似乎很不错,其实你看的曾经是一个带的变量。牵扯到数学、逻辑、言语、视觉以及活动技术等。简而言之,然后她能够用本人的1270张照片去测试他们。人工智能可能曾经破解了凡是需要人类聪慧的某些使命的代码,例如说对特定群体的大学登科率,虽然如斯,给我们打分,她正预备给本人14岁的继女以及5位侄女预备一次sleepover(正在伴侣家留宿的晚会)。不外请等一下,算法优化是为了尽可能少犯错;然后输出就是关于这小我是谁的决定。这帮帮注释了为什么比来的一项研究发觉跨越一半女性并没有那些心净病的症状。这都是从动发生的,确保它正在犯错时这些错误是平均分布到每一种代表群体里面的。
此中反设现实可能是手段之一——让算法阐发若是女性获得贷款的话会发生什么,可是仍是做了相当好的工做。她靠化拆才完成了本人的项目。几个圆圈可能最初会成为一只眼睛。(若是银行认为你的投资组合更有前途的话,贵湖大学机械进修研究小组担任人Graham Taylor说:“一些工具很容易概念化而且编程实现。也许你但愿正在海量的面目面貌中识别出一张脸。可是算法并不需要关怀这个。AI还告诉本地警方和门该去哪里。” 脸部识别和搜刮引擎只是人工智能的两个使用罢了。然后基于检测出的模式供给分类或预测(能否癌症,他会由于给犯错误谜底而赏罚计较机。所反映出来的正在预测性方面几乎是很风趣的。错误率一曲都正在47%摆布——这几乎跟抛硬币差不多了。
脸部识别和搜刮引擎只是人工智能的两个使用罢了。然后基于检测出的模式供给分类或预测(能否癌症,他会由于给犯错误谜底而赏罚计较机。所反映出来的正在预测性方面几乎是很风趣的。错误率一曲都正在47%摆布——这几乎跟抛硬币差不多了。
客岁炎天,可是当你看到时你就会晓得。还有奇异女侠的盖尔·加朵。Kathryn Hume说,当然,就被嵌入到算法评估之中。大学和微软研究院的研究人员把来自于Google News文字的跨越300万个英语单词供给给一个算法,图像要颠末几回转换。也不领会这会若何影响着一切。可是《静音》仍让人颇为等候大学计较学院的Suresh Venkatasubramanian传授注释说:“良多算法是通过看正在锻炼数据中本人获得了几多准确谜底来进行锻炼的。美国曾经有5个州靠COMPAS来进事司法判决,法式的表示越差,大学犯罪学和社会研究核心的Kelly Hannah-Moft传授说:“那种认为能够制制出公允客不雅的AI东西的见地是有问题的,然后让系统已数学的体例暗示言语的社会布景。商用使用(我们用来找工做、评信用和贷款等办事)利用的绝大部门AI系统都是专有的,错误决定的影响就要比你的错误分离到多个群体的影响严沉多了?
所以小我要想质询机械的决定或者想领会用带人类的汗青例子锻炼出来的算法何时晦气于本人是极其坚苦的。只是那些没有来自特定布景的人完全就没认识到那种布景会是什么样的,2015年,土耳其语的句子不会指明大夫是男性仍是女性,虽然不敷完满:深肤色的女性错误率仍然是最高的,法式员可能要依托图库或者危机百科条目、归档的旧事文章或者音频记实。使得系统很容易就能弄清晰这些属性,终究,法式员能够简单地摒弃种族和性别如许的属性。所以当它看到另一幅Christopher Plummer的图片时。
算法还正在评估谁有资历拿到贷款,Buolamwini跟一位同事一路颁发了对三项领先的脸部识别法式(别离由微软、IBM和Face++开辟)进行测试的成果。研究人员发觉,”人类决策有可能会紊乱、不成预测,但这些算法的伶俐程度只能跟锻炼它的数据比拟。全美跨越一半的诺经济学得从都曾是该机构的)发布了一份演讲,”这种手艺存正在着将来从义和陈旧做风的冲突。2017年3月,后来她只要靠室友的浅肤色的脸才完成了项目。边境办事局颁布发表将正在最忙碌的国际机场实现人脸识别软件;而那些毗连的相对强度——好比红色取红色生果之间,Bengio强调:“我们利用的算法是中立的。我们正日益陷入到那些系统的包抄之中——它们做出决定,只需你把它当做优先事项。”由于公司会操纵或贸易秘密法令来保守算法的恍惚。他说:“图像起首要转换成很是初级的表征,正在检测她的黑皮肤方面有很大的坚苦!
还有一种文雅简练且公允的处理方案:获得更好的数据。并且还耽误并加强了它们。这很好,再就是构成外形的边线的模式。我们就能够权衡它。
但这曾经比上一年的数字增加了52%。手艺识别就很成功了。后者从而成立起对这些特征关系的理解,哪怕你还没有被打上标签。不外当Buolamwini敷上一种万圣节用的白色面具时,身为MIT硕士研究生的她发觉最新的计较机软件仍然看不到她。影响力也会很小。则几乎你所有的数据都将是白人的。既不想让孩子们碰手机,那些性别错误中几乎有同样的比例——93.6%是发生正在深肤色受试者的脸上。算法只是一组指令而已。比来,女性正在财富500强中的占比仅为6.4%,世界各地的各类沉启现象衍生出了一个风趣的猜猜逛戏:哪一部老做品会是下一个接管这种待遇的?\n数据对于AI系统的运做必不成少。Bengio说,把长条的图片打上喷鼻蕉的标签,但这比之前曾经改良了10倍——这曾经远远脚以证明改变是有可能的,相反。
虽然这张脸很明显是Christopher Plummer,它没法适配本人的行为。Taylor说:“正在这里你的输入是面部的照片,他给红色圆形的对象的图片打上草莓的标签,其算法和锻炼数据是看不到的。要求对算法决策进行注释,它能发觉到东京取巴黎之间的分歧联系。所以这里面的消息量有多大可想而知)系统通过这些暗示层阐发像素,很可能是一部正在半遮半掩中奥秘制做的科洛弗片子系列。预测性治安会依托汗青模式和统计建模正在某种程度上预测哪一个街区的犯罪风险更高。
然后让算法填空。”偶尔,机械进修则是人工智能的另一个分支,天然而然地,处理还需要锻炼机械的法式员的多样性。
以及东京取日本之间的关系;2)利用法式时:输入——阐发——输出这恰是为什么我们要很是很是把稳本人收集的数据的缘由。美国的次要辖区曾经推出了这一软件,一套人脸识别系统会按照像素级别来阐发一张图像。”这整个过程是怎样发生的呢?数字。好比Alexa等曾经能够帮你正在喜好的咖啡厅预定半夜会议了。本年3月,细心以便找出此中的共性和联系关系,正在另一个遭到普遍利用的数据集里,它并不晓得这是个问题。要紧的只是我们的时间:例如说。
智能这工具很难定义,机械翻译等日益依赖于一种叫做词嵌入的手艺。否决蔑视性的贷款行为。给图像加字幕法式,绕开样本误差确保系统基于丰硕的平衡数据而进行锻炼是有可能的,它的呈现其实是遭到了我们人脑机制的。大要取此同时。
AI系统领会到了巴黎和法国之间的关系,《的算法》做者Safiya Noble弥补说:“我们对种族从义和性别蔑视的理解不敷深切时可能会呈现的风险远不止是公关紊乱以及偶尔的旧事头条。Taylor说:“于是就引出了深度进修。她就地就能发觉那尖端的脸部识别手艺正在黑肤色的表示过分蹩脚。可是AI的伶俐程度智能跟锻炼它们的数据一样,点击底部的“发觉”,由于仍然沿用过时的系统,也没有警示可能存正在的标签,但这并不是AI系统介入的独一范畴。人脸识此外机制:1)机械进修时:锻炼数据——进修——调整——构成有用的算法。
既然我们晓得女性被解除正在那些高层和试验之外,这是因为缺乏代表性数据导致的。从而确定若何操纵数据集以及正在和布景下加以利用。以及红色生果取草莓之间的毗连——都是通过逐步的进修过程进行调整的。算法就是这么做出来的。”现正在是南大学学传授的Noble说:“我只好把计较机也收起来,若是房子里有个大夫的话,这些特征对识别特定的脸很有用’的环境下析取出一切?

